First, I made a new subset for the females from the original data, Dataset, and named it “females”.
>females <- subset(Dataset, Sex == “Female”)
I made a new object, ag, and used ddply to take the subset “Sex” from the object “females” and appended on the average grade by declaring transform as an argument. Ddply is part of the plyr package and follows a convenient naming convention that dictates the input and output data types. The first two letters determine if the respective input and outputs are an array, list, or data frame. They can also consist of multiple inputs or no inputs.
ag = ddply(females, “Sex”, transform, Average.Grade=mean(Grade))
Next, I saved a file of the data with the write function. Notably, it saves to your default directory for documents, and without a file extension added onto it. Using the argument sep=”,” will make the file a CSV file, which I found neat since CSV stands for comma separated values.
write.table(ag, “Sorted_average”, sep=”,”)
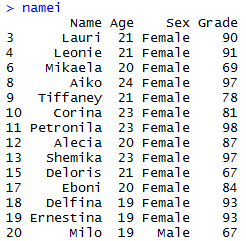
I made a new subset, namei, of the original dataset and used the grep() function to add the values from the column “Name”. Adding an “l” onto grep makes defines each value for the vector as either a match or mismatch (logical).
namei <- subset(Dataset, grepl(“[iI]”, Dataset$Name))
Finally, we can recall namei to see the printout of the table of all those i-named folk.