
Machine learning grew out of the still-young field of artificial intelligence (AI). As artificial intelligence progressed, it began relying more heavily on making AI’s that used information that was hardcoded into it while using a probabilistic approach was plagued with issues of how to gather and make use of data. In the 1950’s, MIT researchers Farley & Clark (1954) and IBM researchers Rochester, Holalnd, Haibt, & Duda (1956) began trying to employ artificial neural networks to improve their functions. Computing limitations would hold back the progress of machine learning for several decades, which marked the beginning an era known as AI winter (Sebag, 2014, p. 14). This caused a divergence from AI, and led to machine learning falling to the wayside. In the 90’s, increased computing power allowed for better modeling and processing of data and for machine learning to start gaining some more traction. In addition to the increase of raw computing power, the internet exploded in the 1990’s and 2000’s. This propulsion into the information age made an unprecedented amount of data available and ripe for processing and, with that, machine learning found a new set of legs to stand on.
Generally, machine learning algorithms can be classified into three different paradigms or methods for solving problems: unsupervised learning and supervised learning. In unsupervised learning, the data is data that is unlabeled, the computer doesn’t know how they relate, but has some property to it. The algorithm must then figure out how the data’s properties group together, making clusters. Essentially, your algorithm is trying to classify its inputs. In supervised learning you have labeled data that you put into your algorithm and then, hopefully, your algorithm outputs some new relational data for it. In other words, you know what the items are but don’t know how they fit together. Another method of machine learning is reinforcement learning, which is where your algorithm has a set of rules and a goal or problem and it has to find the best way to solve the problem. Each of these methods has many different models of algorithms that it can employ to help reach its objective.
One model of machine learning is the artificial neural network. The artificial neural network was originally modelled after how we thought the neural networks in our brains work, consisting of neurons and axons. The aim is to create a network of neurons that are adaptive and have different weights to determine how they alter an input. Initially, a topology is made for the network with there being connections between every neuron and then, over time, these neurons and axons adjust to the inputs by altering their weights. The strength of neural networks is in their flexibility and capability to process complex data. An interesting take on neural networks is a method called NeuroEvolution of Augmenting Topologies (NEAT). According to Stanley & Miikkulainen (2002), “connection weights are not the only aspect of neural networks that contribute to their behavior. The topology, or structure, of neural networks also affects their functionality… If done right, evolving structure along with connection weights can significantly enhance the performance of [NeuroEvolutions]… If structure is evolved such that topologies are minimized and grown incrementally, significant gains in learning speed result. Improved efficiency results from topologies being minimized throughout evolution, rather than only at the very end (p.100)”. Traditional neural networks don’t alter their topologies once they start evolving, but that’s where NEAT makes its difference. Allowing the alteration of the topology serves to keep the overall simplicity of the network in order to gain increases in performance. If a neuron isn’t contributing, then NEAT is able to get rid of it altogether and save the system from unneeded processing power. An interesting implementation of this idea is MarI/O.
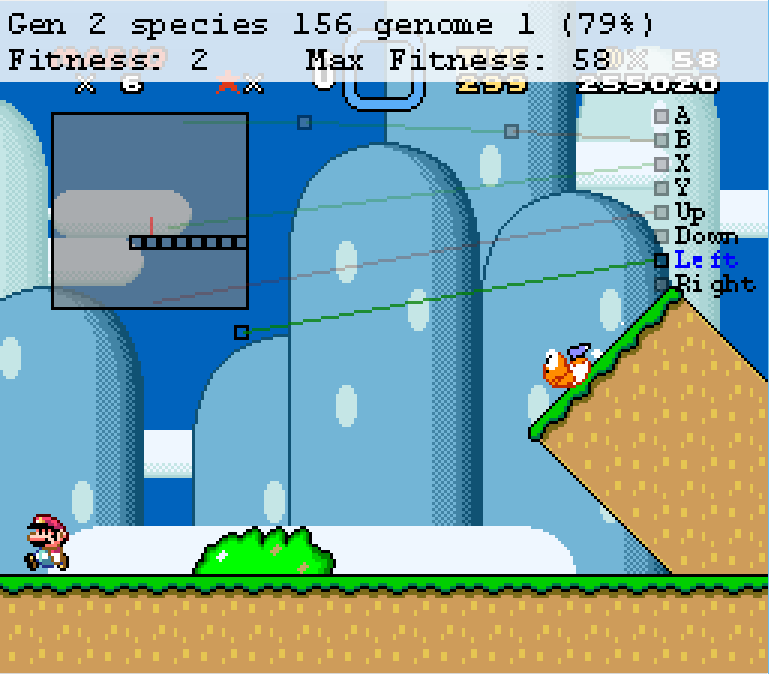
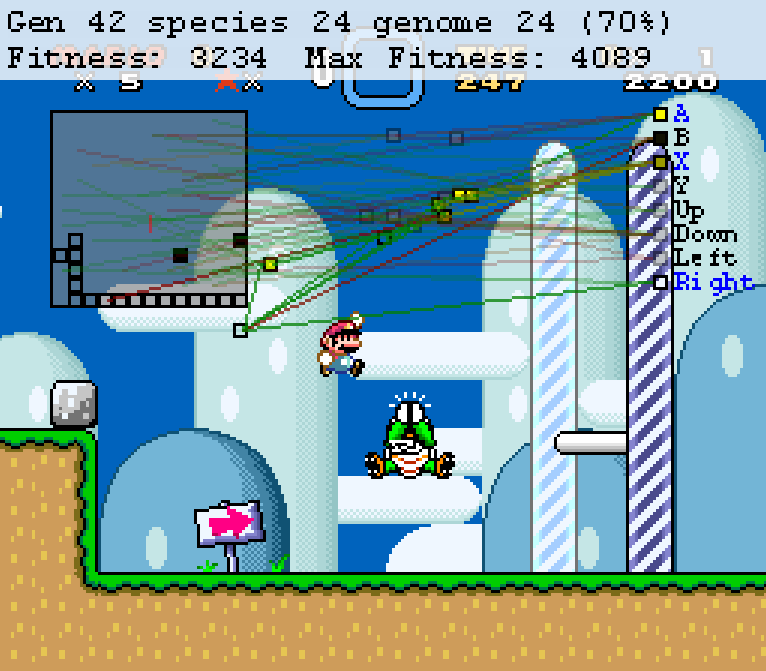
Figure 1. Mario at the start of Yoshi’s Island 1.
MarI/O (SethBling, 2015) is a LUA script that teaches a computer how to play the game Super Mario World. The computer starts off with absolutely no information. It knows nothing about what the eight input buttons that it is given do, nor does it know what the objective of the game is. Each attempt makes subtle, random, evolutions in the genome of how the script acts in order to achieve a higher fitness score, which is a measure in how far Mario gets through each level. An attempt comes to and end either with death, or with a period of time in which there is no activity in the fitness score. Over the course of thousands of attempts (completing one stage takes around a day of processing), successful genomes with high fitness scores are bred with each other to make new species and then species are culled into new generations of the script.
The MarI/O GUI shows us many things about the neural network. To start, the little translucent squares are ground that Mario is able to walk on, while the black squares (Figure 2) are moving objects, which can be either enemies or power-ups. On the right side are the neurons that trigger the respective outputs, and in the middle are more neurons as well as lines that activate the neurons. In Figure 1, you can see some of the triggers of the current genome as translucent red or green lines pointing to a spot on the map on the top left of the screen, which is what the input as well as what computer sees. These are read, by the script, from the associated addresses that the sprites are stored in inside the memory.
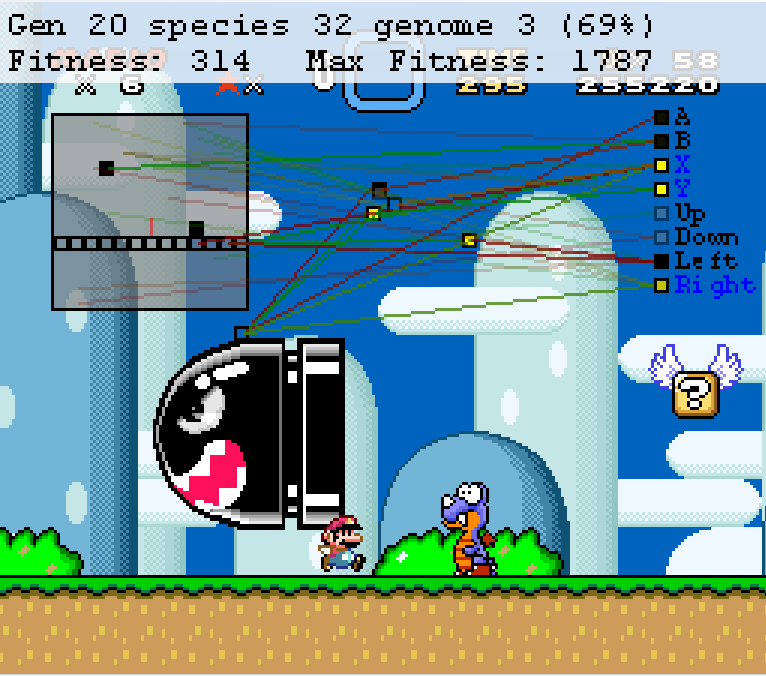
Figure 2. Mario encounters enemies near the beginning of Yoshi’s Island 1.
The green line is a positive connection and will turn the neural nodes to the same color as the square it touches on the map. A red line is a negative value and will flip the value of the neural nodes to the opposite of what it touches. When the output neurons are activated by a clear square, they press either press or hold the button down, depending on how long the neurons are active for. If an output node is turned black, or negative, then nothing happens and the button is not pressed. A neuron that is yellow is being activated by both positive and negative connections. This will only cause a button press when the positive connection is triggered. Therefore, if a button is being held down from a positive connection and is activated by a connection that would flip its value, then the button will turn yellow and not black. At the top of the figures, you will see all of the information about MarI/O’s evolutionary progress displayed as generation, species, as well as genome. Additionally, you can see how successful Mario has been. The fitness measure is a function of how far Mario has traveled on the X-axis compared to the amount of time left in the level and it also includes a large bonus if the level is completed. Notably, coins and the in-game score do not contribute to the fitness score. This measurement is the feedback that drives the evolution. Higher values come from stronger genomes that will, in turn, be saved from culling and be bred with other successful genomes. Successful genomes will then be culled and bred to create the new species which will also go through the same process to form new generations.
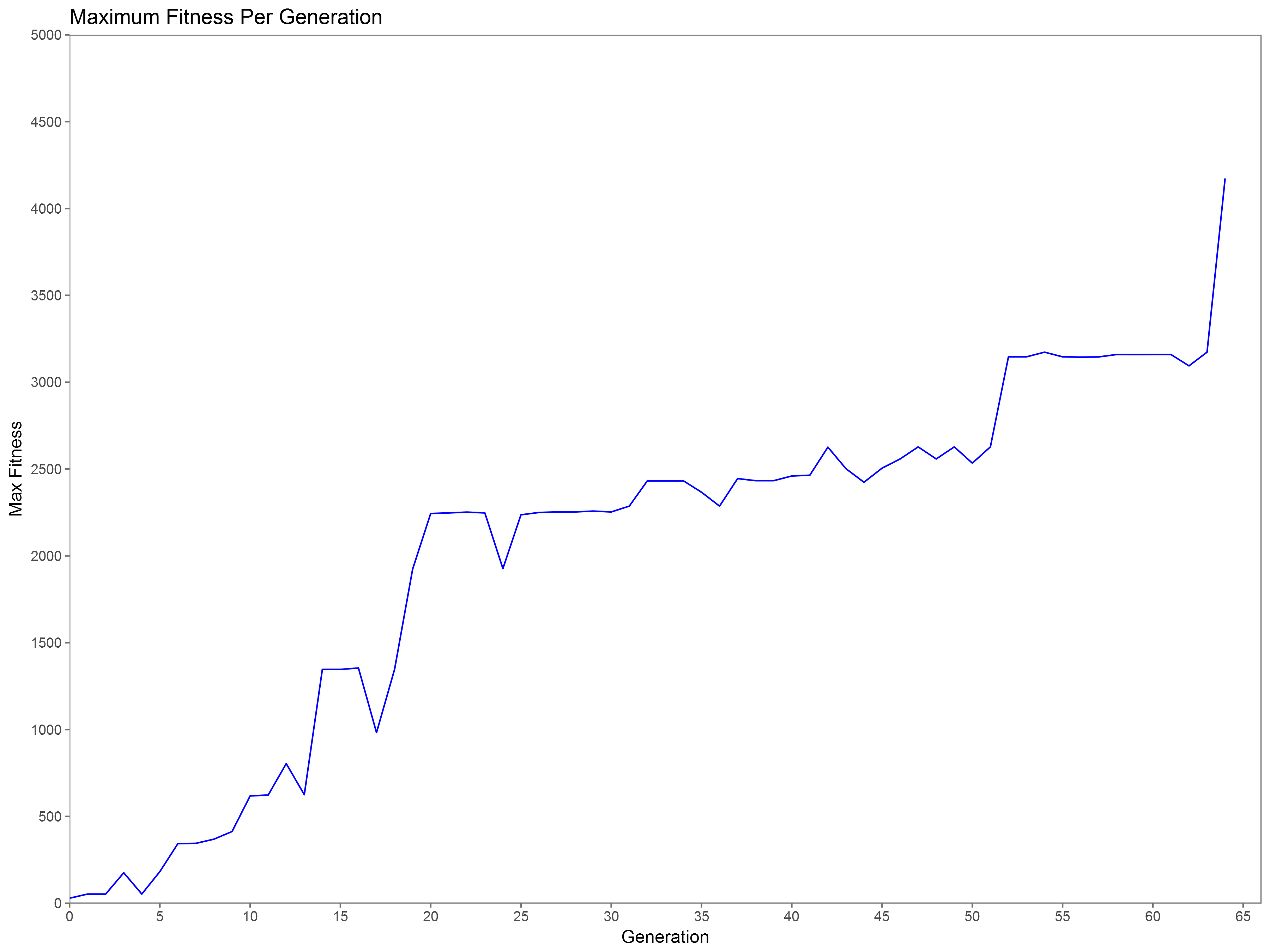
Figure 3. Yoshi’s Island 1 progress to level completion.
I recorded data on 6 different levels of Super Mario World across 60,506 iterations of MarI/O. The first level, Yoshi’s Island 1 (Figure 3), took 16,251 attempts of the algorithm spread across 64 generations. You can see from the graph that the first 4 generations (this is 930 attempts) have nearly no movement. This is due to MarI/O trying to figure out what buttons do. It starts off by going through hundreds of random combinations of neurons and connection combinations before it can even figure out that it needs to press the right button to start to improve its fitness. You can see this in Figure 1 as the algorithm attempts to press left. Once it establishes a neural connection to make Mario go right, it quickly encounters a set of enemies (Figure 2) in which he has to not jump, in order to go under the Banzai Bill, but jump over the Rex. This proves to be a difficult challenge, as the algorithm tends to favor neural networks that lead to Mario constantly jumping so that it can avoid hitting enemies. However, in this case, he has to evolve to not jump in order to get under the Banzai Bill and then selectively jump when detecting the Rex in front of him. MarI/O gets stuck on this until Generation 10. After he gets past this, he approaches a Rex coming down an incline (Figure 4)[1] that gets him caught up until Generation 14. The Rex’s position higher up prevents the neuron from the previous Rex jump to fire, causing MarI/O to have to make a new connection. Clearing this Rex lets him get a large amount of fitness, doubling his score from Generations 13 to 14.
-

- Figure 4. An elevated enemy causes problems.
-

- Figure 5. A pipe requires a different approach for jumps.
-

- Figure 6. A larger pipe needs even further improvement.
The next trial is a simple set of pipes, as seen in Figures 5 and 6, which will hang him up until Generation 21. The cause for this delay is that the things he’s learned to jump over have previously been negative (black) nodes. The pipes show up to the algorithm as positive (clear) neurons, so it has to form new connections to deal with this. Clearing this pipe allows MarI/O to increase his fitness 228% from generation 17 to 20. Up until now fitness growth has been nearly exponential, due to having the algorithm learn most of the basic paradigms of Mario level design: jumping over enemies and walls. From this point on, the growth is incremental and from Generations 20 to 51, the algorithm only manages to increase its fitness by 431 points. The pipe in Figure 6 causes a small, but notable delay around Generation 32. This pipe is slightly larger than the previous one and requires a full-length button press, but the rule learned from the last pipe doesn’t quite give enough of a press to deal with it, causing a need for further refinement. The next roadblock is around Generation 52 where a series of Rexes and platforms (Figure 7) inhibit progress. MarI/O has previously established rules to jump over enemies and land on the same elevation or, in the case of Figure 4, a higher elevation. This series of ledges causes the enemies to now be below, and above Mario.
-
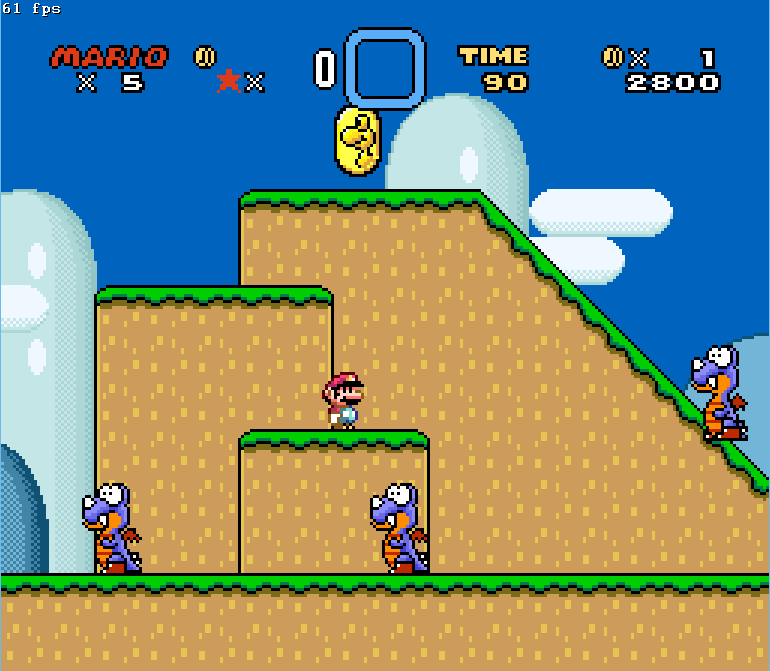
- Figure 7. Mario meets a group of enemies and platforms.
-

- Figure 8. Mario falls into a ditch and has to wait for a Banzai Bill.
-
- Figure 9. Mario completes the level!
If he jumps up on to a platform, he may no longer have a trigger for movement. If he jumps to the top and slides down the incline, he gets killed by a Rex. If he continues as he is positioned in Figure 7, he runs the risk of ending up under the Rex on the incline and then jumping into him. MarI/O has to evolve to navigate this, safely. Directly after this is another Banzai Bill (Figure 8) that poses a challenge for the algorithm. Previous to this, he was able to either walk under the first Banzai Bill or jump over him with a ledge. In this case, he falls in to a ditch and has to wait for the enemy to pass overhead. This is the last major hurdle and takes 12 Generations, up to generation 64, to be able to clear and is notable because it is the first time that MarI/O has to establish a rule for an obstacle that is behind him. Unseen from the figure is a hole that the algorithm would jump directly into after Banzai Bill passed. Getting past these brought Mario upon a few things that were now trivial for the algorithm, and was able to clear the level (Figure 9). Interestingly, this level proved to be the most difficult out of the 6 that I ran to completion. I believe this is due to the diversity in the level. There’s a large variance in how you deal with encounters. For example, Yoshi’s Island 2 and 4 can both be completed by just jumping your way through. The algorithm doesn’t have to worry about ducking under projectiles, having enemies come at it from above, stalling on an incline and sliding down it, or having pits to jump over. I believe it was intentional of Nintendo to design Yoshi’s Island 1 like this, as to show the player a lot of the of the design features that they should expect throughout the game.
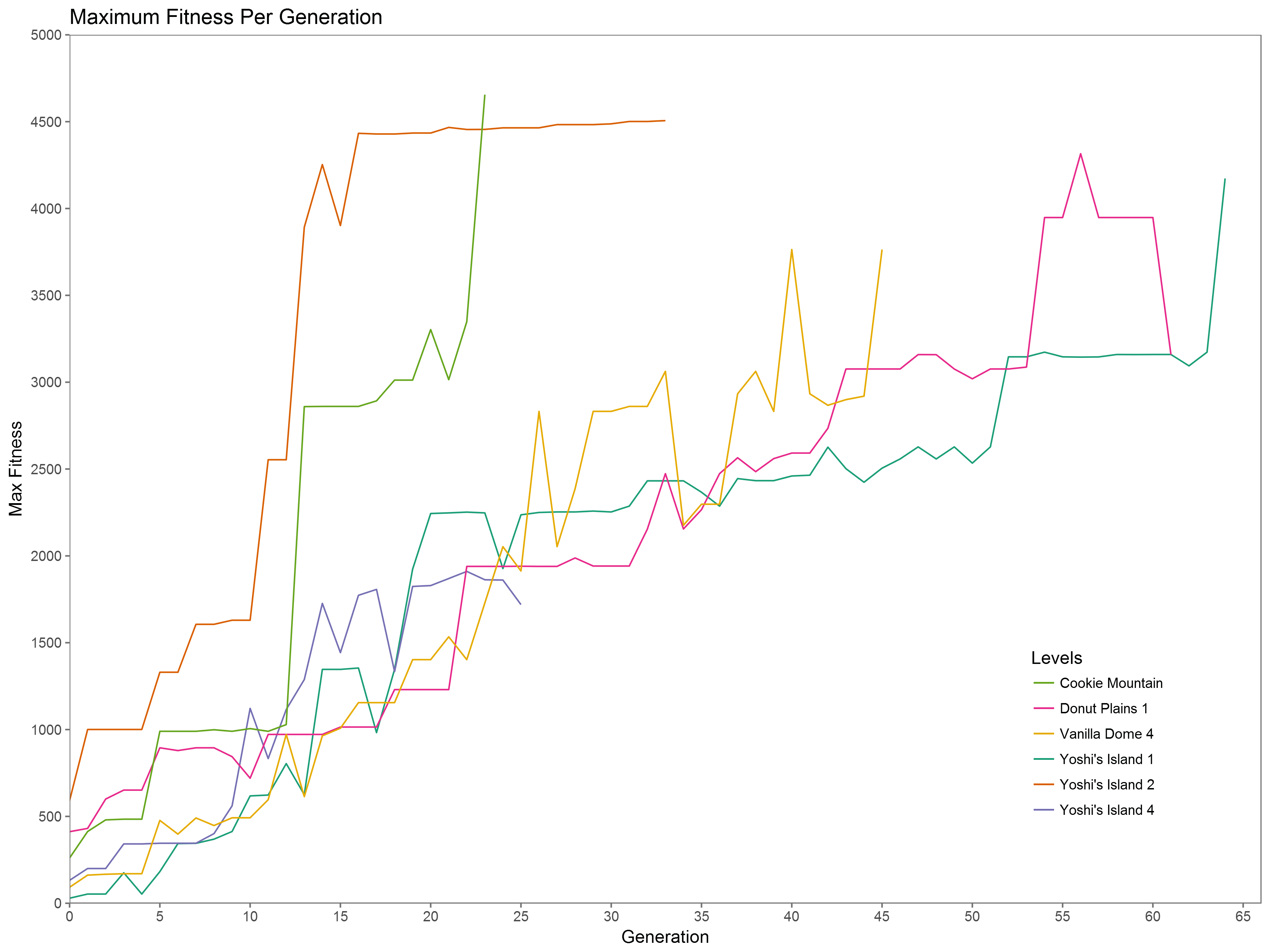
Figure 10. Progress to completion compared across levels.
Overall, MarI/O did well. It was able to complete a good number of levels and was addictive to watch. It even managed to do several glitches including glitching straight through a slope, wall jump[2], and stomping an enemy with his head[3]. However, as well as MarI/O did, it has considerable weaknesses. The mapping system used for the neural network is very rudimentary. In Figure 2, you can see that the size of the Banzai Bill compared to his neural representation is not even close to being an accurate representation of the size of the threat. Additionally, Figure 11 shows how little the algorithm can actually see in some levels. On both sides of Mario are platforms. The one on the left moves horizontally and the one on the right swings like a pendulum once Mario steps on it. Neither one appears on the map as a positive or as a negative neuron, so MarI/O will never attempt to interact with them. Additionally, the coins on the left don’t show up on the map at all. This doesn’t have a big impact on level completion but, it is a departure from watching a human play.

Figure 11. MarI/O can’t see on Yoshi’s Island 3!
Something that isn’t in a figure is that power-ups only show up as negative neurons and are indistinguishable from enemies. This has a much larger impact than the coin issue since having a power up can be the difference between life and death. Another deficiency of MarI/O is that the fitness measurement doesn’t allow for Mario to do levels that require you to move to the left or move a large distance vertically. For example Yoshi’s Island 3 (pictured in Figure 11) starts with a mountain that you have to climb up before you can move to the right. This yields no fitness score, so the algorithm will abort the attempt and restart. The biggest issue with the algorithm is probably that it’s only able to do one level at a time. The way it sets up the neural network doesn’t look like it is possible to complete several levels with one network.
MarI/O is a fascinating algorithm to watch evolve and makes it easy to visualize how neural networks work. Machine learning is making big impacts in virtually every kind of technology we use. With the rise of automation and increasingly capable computers and robots, the usage of machine learning will only become more ingrained in our lives.
References
Carbonell, J. G., Michalski, R. S., & Mitchell, T. M. (1983). Machine Learning: A Historical and Methodological Analysis. AI Magazine.
Farley, B. G., & Clark, W. A. (1954). Simulation of Self-Organizing Systems by Digital Computer. IRE Professional Group on Information Theory, 76-84.
Mitchell, T. M. (1997). Machine Learning. New York: McGraw-Hill.
Rochester, N., Holalnd, J., Haibt, L., & Duda, W. (1956). Tests on a Cell Assembly Theory of the Action of the Brain, Using a Large Digital Computer. IRE Transactions on Information Theory, 80-93.
Sebag, M. (2014). A Tour of Machine Learning: An AI Perspective. AI Communications, 11-23.
SethBling. (2015, June 13). Retrieved from http://pastebin.com/ZZmSNaHX
1. For Figures 4-8, I forgot to take screenshots while MarI/O was running. For Figure 9, the original screenshot I made didn’t have the overlay for the script, so I did another run to show what a level-complete neural network looks like. Therefore, you might notice that the fitness information doesn’t correlate to the original data for Yoshi’s Island 1. ↑
2. If Mario jumps at a wall at max speed, and hits it between two environment blocks, he will momentarily clip into the environment and be able to jump off of an otherwise vertical surface. ↑
3. When Mario is falling, it puts him into a state that allows him to stomp on enemies. Having an enemy land on your head while you’re in this state will result in the enemy getting stomped. ↑